Data and AI are transforming private markets, and secondary investors are actively participating in this revolution. Leading firms like Coller and Landmark (now Ares) have been enhancing their data science capabilities for years. Now, new players such as Clipway are making data and AI the foundation of their investment strategies.
How is the $100 billion secondary market evolving? What new opportunities and risks are emerging? Is the transformation driven by data and AI just hype or a new reality?
In this blog, we will get to the heart of these questions.
 Secondary processes from first principles:
Secondary processes from first principles:
To see how data and AI fit in, let’s first understand a traditional LP-led secondary process from the ground up.
The goal of a secondary investment process should be to close as many high-quality deals as possible, as efficiently as possible.
In theory, this can be achieved via a combination of two levers:
- Evaluating as many deals as possible, i.e. maximizing “opportunity coverage”; and
- Ensuring that the process eliminates bad deals and advances good ones, i.e. improving “deal selection”.
| Deal Quality = Opportunity Coverage × Deal Selection |
In practice, both levers are highly resource-intensive, and firms have limited resources:
| Resources = Investment Team Size × Tech Stack |
This creates a trade-off between coverage and selection skills:
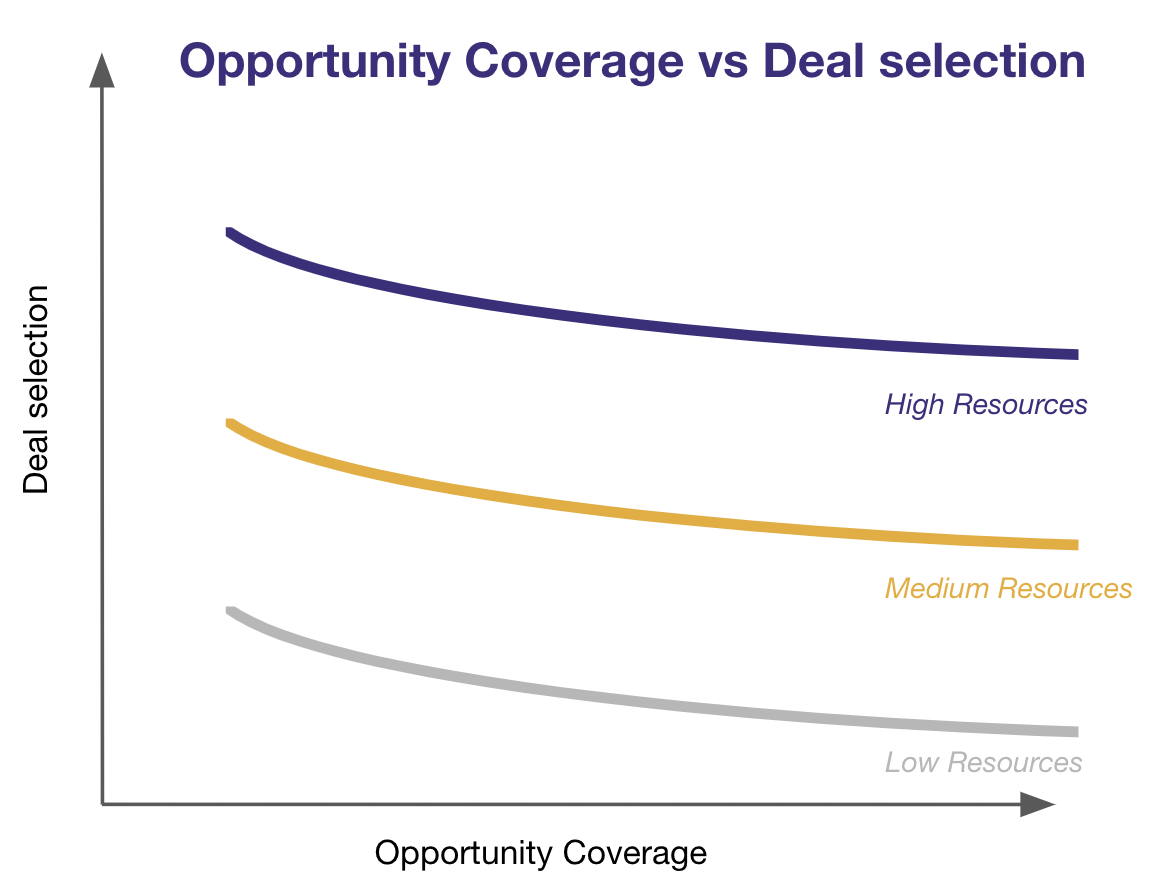
For a given level of resources, spending more time sourcing deals means less time for due diligence, and vice versa.
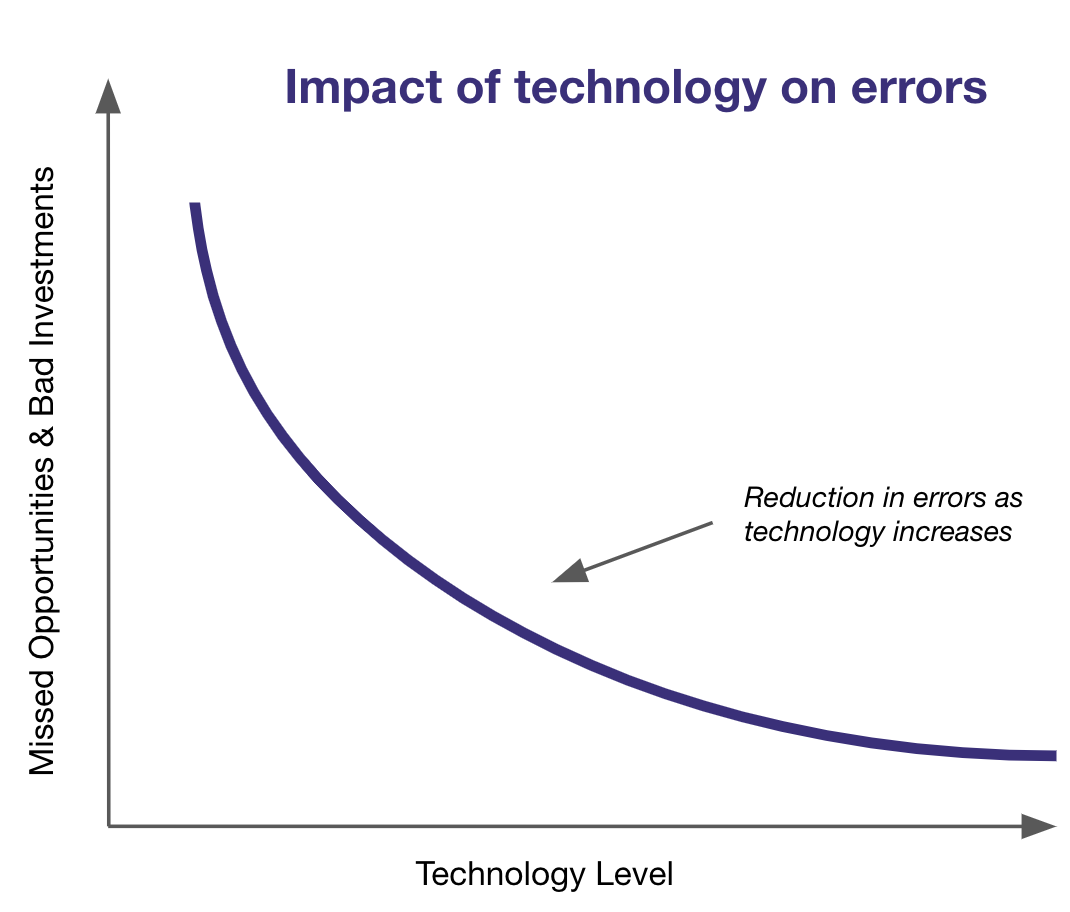
Due to these constraints, secondary processes often resemble a "deal sift," where focus narrows to the most promising deals as they progress through different phases. The aim is to allocate resources wisely, minimizing 2 types of errors:
- Missed opportunities: these are deals that are discarded but end up performing well. Warren Buffet would call them “errors of omission”, a data scientist would call them “false negatives”
- Bad investments: these are deals that are pursued but end up performing badly. Warren Buffet would call them “errors of commission”, a data scientist would call them “false positives”
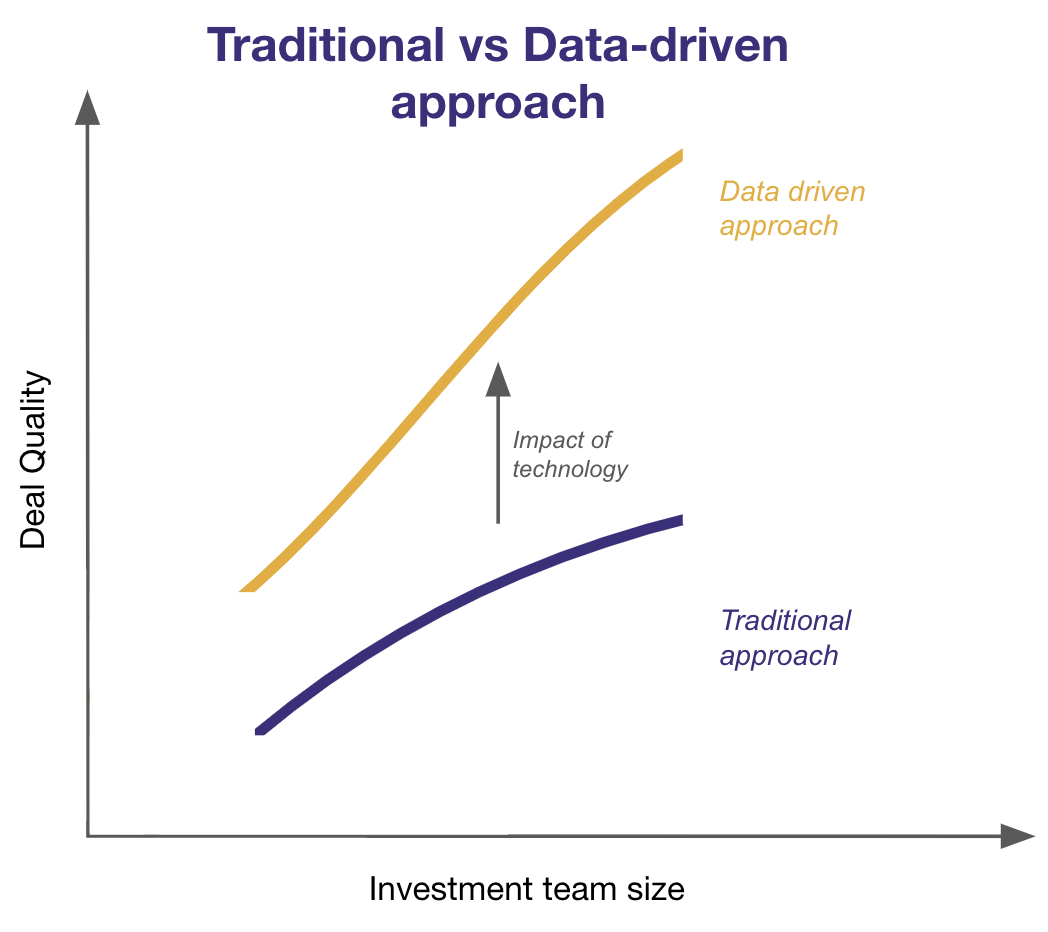
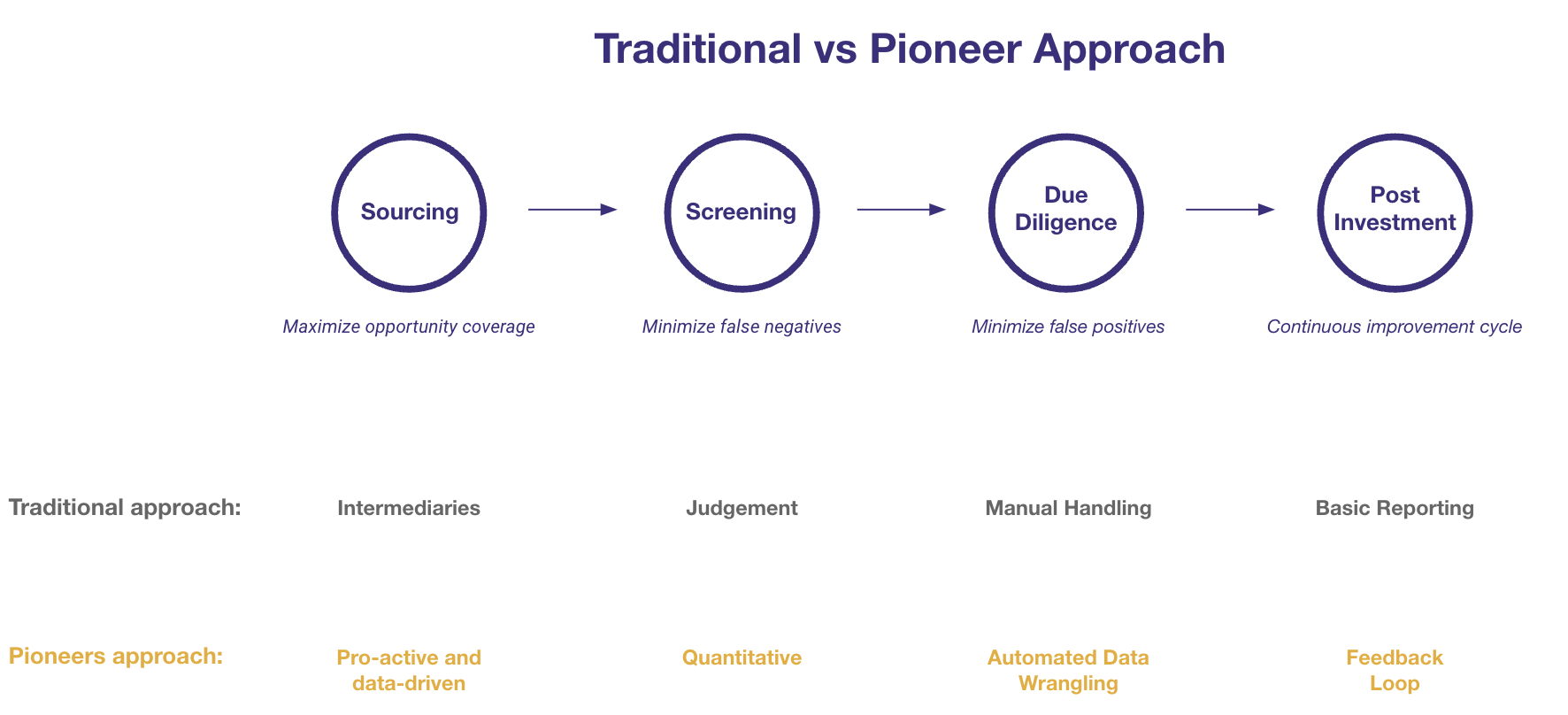
The traditional vs data-driven secondary approach
Firms can relax the resource constraint by either expanding their team or upgrading their technology.
Traditional secondary investors approach the problem by brute force: they mostly rely on judgment by investment professionals, and make very little use of data to inform decisions and technology to deliver efficiency.
Data-driven pioneers, on the other hand, leverage data and technology to push the resource constraint and improve deal quality:
Approaches: Traditional vs Pioneer
Sourcing
Traditional players typically source the majority of their deals through intermediaries, which often results in missing out on many "off-market" opportunities, limiting overall coverage. While fostering good relationships with LPs can help identify "off-market" opportunities early, this approach is not scalable and is unlikely to produce systematic benefits due to the vast number of potential LPs.
In contrast, data-driven players leverage data and analytics to proactively generate new deals. They might, for example, maintain a database of LPs’ target and actual asset allocations to estimate which LPs are most likely to initiate sales processes due to denominator effects. Based on this information, they would launch proactive sourcing campaigns. Additionally, they would use advanced CRM systems to streamline outreach efforts, automating tasks such as email follow-ups, thus saving valuable time for their investment teams.
Screening
Weekly deal flow calls are a common forum for reviewing the backlog of opportunities and deciding which deals to progress and which to discard. Traditionally, these decisions are based on the instincts of senior investment professionals, who consider factors such as the quality of the GP, the likelihood of closing the deal, its fit within the current portfolio, and the potential upside. This triaging approach can efficiently produce decisions and ensure that valuable investment team resources are not wasted on unsuitable deals. However, there is a high risk of error and bias, as decisions may be influenced by convincing but misguided narratives rather than evidence-based arguments. This increases the risk of ignoring promising deals (“false negatives”).
Data-driven players aim to bring as much data as possible to these discussions, seeking to eliminate bias, maximise deal coverage, and minimise false negatives. They may use high-level information on the deal and current portfolio to quickly assess if the deal might breach any portfolio construction metrics or negatively impact performance indicators. Additionally, they might use third-party pricing data and internal models to evaluate the potential upside of the deal. Since sellers typically share little information at this stage, leveraging previously collected data is crucial.
Due diligence
After the screening phase, it is time to perform detailed due diligence, where most of the investment team's energy is expended—potentially on the wrong deals. The key is to minimise false positives as efficiently as possible. Traditional teams tend to spend 80% of their time on data wrangling—sifting through data rooms, extracting data from PDFs, and inserting it into spreadsheets—leaving only 20% of their time for modeling, which is the real value-adding part of the process. Due to the resource-intensive nature of this phase, teams often take shortcuts, such as modeling only the top 90% of the NAV for diversified portfolios or ignoring bottom-up dynamics. These approximations can lead to mispricing, resulting in lost deals and higher resource waste for underpriced bids or lower-than-anticipated upside for overpriced deals.
Data-driven players re-engineer the due diligence process to ensure that investment teams spend 80% of their time on understanding and modeling the deal rather than on menial tasks. They achieve this by minimising the pain of data wrangling, ensuring all relevant data is readily available in a clean format and ready for use. For instance, they may automate the extraction of company data from data rooms, fetch transaction or public comps for bottom-up pricing, and estimate financial upside based on historical data.
Advanced algorithms can automate pricing logic and performance estimates, ensuring accurate and efficient valuations. This reduces the manual effort involved and allows analysts to concentrate on strategic, value-added activities.
Post investment
Building intelligent data and analytics systems is only half the challenge; the other half is continually refining them based on past mistakes. To achieve this, deals must be tracked after closing, and any discrepancies from the initial model must be fed back into the system to strengthen the process. Traditional players have largely neglected this area, effectively ignoring the deal post-closing except for reporting requirements.
In contrast, secondary pioneers recognize the importance of harvesting and leveraging this data. They upgrade monitoring into a dynamic, strategic endeavor through continuous data collection and model refinement. This ongoing feedback loop ensures their systems become increasingly accurate and effective over time.
Conclusions
The secondary market in private equity is undergoing a profound transformation driven by data and AI. Traditional approaches, characterized by manual processes and inefficiencies, are giving way to a more streamlined, data-driven approach. Firms that embrace this change are poised to lead the industry, while those slow to adapt risk being left behind. By leveraging technology, secondary transactions can be conducted with greater precision, speed, and strategic insight, ultimately benefiting all stakeholders involved.
Want a head start?
Reach out to the Tamarix team to automate your look through extraction.